
学习一下DeepSeek-V3.2

学习一下DeepSeek-V3.2
lycheeKing果然又在放假前发新模型了… 不光是DeepSeek, 还有Claude-4.5(后面再分析吧)
可以看到DeepSeek整个模型依旧延续着Sparse这条路, 这次动刀到了Attention上, 当然有了前面NSA的预期.
这次出现DSA也就很正常了. 实质的问题就是计算本身是很容易ScaleOut的, 而内存访问是很难的. 由此可以看到一个很清晰的脉络, 从最早的模型开始, 使用MoE在FFN上稀疏, MLA降低KVCache用量, 再到Attention本身的稀疏, 在Token上做一些选择, 细粒度(Fine-grained)的专家和Token选择串起了一条非常清晰的路径….
DeepSeek-V3.2-Exp 是一个针对Long Context的实验性稀疏注意力模型. 它的核心创新在于, 通过在现有模型 DeepSeek-V3.1-Terminus 的基础上进行持续训练, 引入了一种名为 DeepSeek稀疏注意力(DeepSeek Sparse Attention, DSA) 的新机制.
另外在训练过程中基于KL散度的方式来处理也很巧妙. 想起愚人节给大家开的一个玩笑.
虽然说是一个玩笑, 其实当时就有一个很简单的数学上的直觉, 能否基于KL散度的方式来构造一些轻量级的Attn计算时的attn score分布逼近于Full Attention. 所以看到Tech Report第二章会心的笑了一下~
另一个值得关注的是Tilelang, 简单的说“利好国产卡”. 其实几个星期前就准备把国庆的时间用来写一些Tilelang的东西, 大概一周前也收到了廖博给我的PyPTO的文档, 当时也觉得挺好的. 于是前段时间开始从CuteDSL学习, 逐渐完善整个领域相关的知识. 相对于Triton, Tilelang有了更好的抽象更细粒度的控制, 对于国产卡的一些生态适配也挺不错的, 后面还有一些TileScale, TileRT相关的项目, 留着整个十月慢慢补吧…
DSA架构
核心问题是解决注意力机制的$ O\left(L^2\right) $复杂度, 标准自注意力机制需要为序列中的每个token计算与所有其他token的注意力得分, 序列长度为时, 计算复杂度为$ O\left(L^2\right) $. 当达到128K甚至更长时, 这个平方复杂度的计算量和内存占用会变得极其巨大, 成为训练和推理的主要瓶颈. DSA的目标就是打破这个瓶颈.其实在Google的MoD论文**《Mixture-of-Depths: Dynamically allocating compute in transformer-based language models》[1]中已经可以观察到其实并不是每个Token都需要参与到Attention的计算**. 同时一些adaptive tempreture的处理也能观察到softmax的一些分布变化.
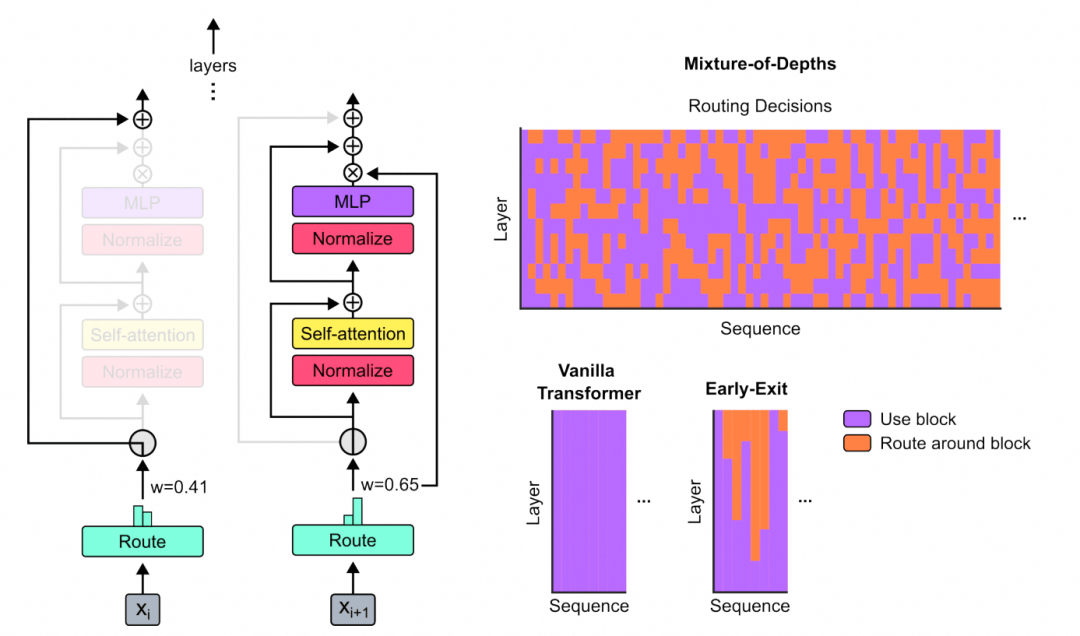
而DeepSeek的做法则是显得更加优雅直观一些. 简单来说就是基于DeepSeek-V3.1-Terminus进行持续训练, 然后引入了Lightning Indexer和Top-K selector实现了稀疏的Token处理.
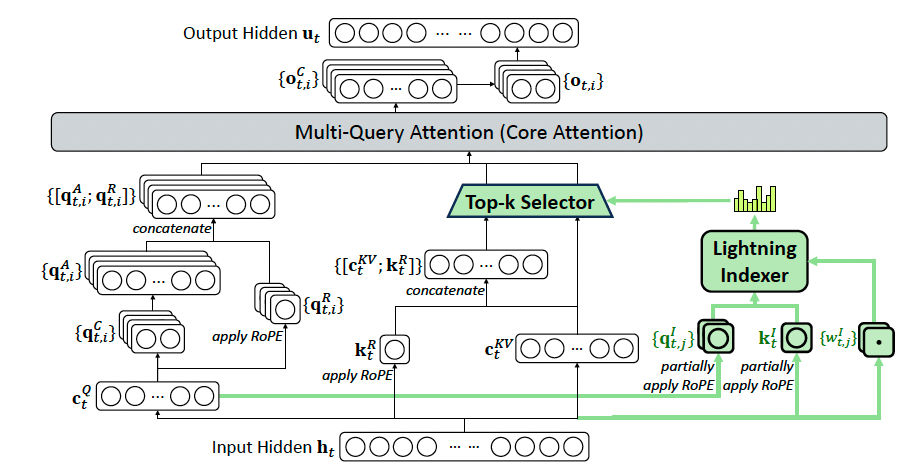
- 绿色路径 (DSA部分): 生成轻量级的 $ q^I $ 和 $ w^I $, 进入Indexer, 经过 Top-k 选择器, 最终输出一个”地址列表”, 告诉主注意力应该去关注哪些历史token.
- 主路径 (MLA部分): 生成重量级的Query Head和当前的KV $ c_t $.
- 融合: 主路径的查询头, 根据绿色路径提供的”地址列表”, 从历史键值对中精确地取出被选中的$ {c_s} $, 并与当前的一起进行MQA计算.
在DSA中. lightning indexer(以下简称indexer),计算查询token $ h_t \in \mathbb{R}^d $与其之前的token $ h_s \in \mathbb{R}^d $ 之间的索引得分 $ I_{t,s} $ , 这个得分决定了哪些token将被该查询token选中:
$ I_{t,s} = \sum_{j=1}^{H_I} w^I_{t,j} \cdot \text{ReLU}(q^I_{t,j} \cdot k^I_s) $(1)
其中, $ H_I $表示Indexer的头的数量; $ q_{t, j}^I \in \mathbb{R}^{d_I} $和 $ w_{t, j}^I \in \mathbb{R} $是从query token 派生出来的; 而 $ k_s^I \in \mathbb{R}^{d_I} $ 是从前序token $ h_s $ 派生出来的. 选择 ReLU 作为激活函数是出于对吞吐量的考虑. 鉴于Inexer的头数量很少, 并且可以用FP8格式实现, 它的计算效率非常显著.
这个公式本质上是一个简化版的, 轻量级的Attn Score计算器. 它不像标准注意力那样使用Softmax和高维度的Query/Key向量.
- $ q_{t,j}^I $ 和 $ k_s^I $ 是低维度(“index_head_dim”: 128)的Query和Key向量, 用于快速计算相关性.
- ReLU激活函数: 这是一个关键的效率优化. 相比Softmax, ReLU的计算非常简单, 对GPU等硬件非常友好, 显著提升了计算吞吐量.
- $ w_{t,j}^I $: 这是一个可学习的权重, 允许模型动态地调整每个Indexer头的贡献度, 增加了Indexer的表达能力.
- $ H^I $ (头的数量=64)很小: 这直接减少了计算量.
- FP8实现: 论文提到可用FP8(8位浮点数)实现. 这意味着计算量和内存占用可以进一步大幅降低. 因为Indexer只需要提供一个相对的排序(ranking)而非精确的注意力权重, 所以它对数值精度的要求不高.
Indexer本身依然是$ O\left(L^2\right) $的复杂度, 因为它仍然需要计算每个查询token与所有历史token之间的得分. 但是, 由于其计算的”单位成本”极低(低维度, 简单激活函数, 低精度), 在实际应用中,它的开销远小于主注意力模型, 因此总的端到端效率得到了提升. 这是一个非常典型的用常数项优化换取整体性能的工程实践.
对于每个query token , 在获得index score $ {I_{t,s}} $ 后, 细粒度token选择机制仅检索与top-k索引得分相对应的KV $ {c_s} $. 然后, Attn score $ u_t $ 通过在query token $ h_t $ 和这些稀疏选择的KV $ {c_s} $ 之间应用注意力机制来计算得出:
$ u_t=\operatorname{Attn}\left(h_t,\left{c_s \mid I_{t, s} \in \operatorname{Top-k}\left(I_{t,:}\right)\right}\right) $(2)
这是DSA实现效率提升的根本所在. 它将主注意力机制的计算范围从整个上下文(长度$ L $)强制缩小到了一个固定的, 大小为$ k=2048 $的子集. Top-k: 它直接保留得分最高的$ k $个token, 丢弃其余所有token. 这种方法的优点是简单高效, 但缺点是可能会丢失一些虽然单项得分不高, 但组合起来很重要的信息. 这是所有基于Top-k的稀疏注意力方法共有的权衡.通过这一步, 主注意力的计算复杂度从 $ O\left(L^2\right) $ 成功降低到了 $ O\left(L×K\right) $ . 由于$ k $是一个远小于$ L $的常数(在第二章中提到$ k=2048 $), 这是一个从二次到线性的巨大提升.
实际上对于整个GPU而言, 访问内存的数量也减少了. 特别的来说, Indexer相对增加的计算复杂度, 和对应的softmax计算量减少更加的匹配了B200这样的芯片.
vLLM在x上也公布了一个图供参考:
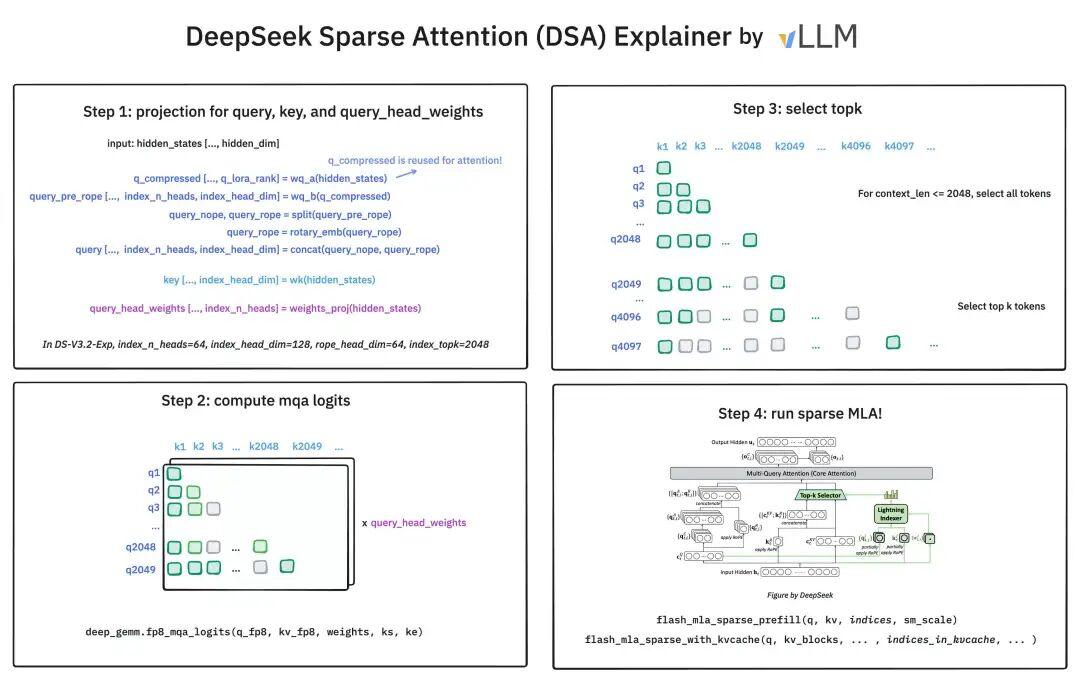
在MLA下实例化DSA (Instantiate DSA Under MLA). 出于从DeepSeek-V3.1-Terminus进行持续训练的考虑, 为DeepSeek-V3.2-Exp在MLA (Multi-head Latent Attention) 的基础上实例化了DSA. 在kernel层面, 为了计算效率, 每个KV必须被多个query共享. 因此, 基于MLA的MQA模式实现了DSA, 在该模式下, 每个潜向量(MLA的KV)将被该query token的所有Query head共享.
作者没有重新训练一个模型, 而是基于DeepSeek-V3.1-Terminus模型上进行”升级”. 这种”持续训练”的思路可以极大地复用已有的模型能力和训练资源. 因此也延续了原有的MLA架构, 使用很低的成本来为未来的Sparse Attn进行探索和实验.
而后面第二章基于KL散度的训练也很巧妙.
训练过程
持续预训练 (Continued Pre-Training)
DeepSeek-V3.2-Exp的持续预训练包含两个训练阶段. 在这两个阶段中, 训练数据的分布与用于DeepSeek-V3.1-Terminus的128K长上下文扩展数据完全一致.Dense Warm-up Stage 首先使用一个简短的warmup阶段来初始化indexer. 在这个阶段, 保持使用dense MLA, 并冻结除Indexer外的所有模型参数. 为了将Indexer的输出与主注意力分布对齐, 对于第个查询token, 首先将所有主注意力头的注意力分数相加. 然后, 这个总和沿着序列维度进行L1归一化, 以产生一个目标分布. 基于这个, 设定一个KL散度损失作为Indexer的训练目标:
$ \mathcal{L}^I=\sum_t \operatorname{DKL}\left(p_{t,:} | \operatorname{Softmax}\left(I_{t,:}\right)\right) $(3)
为了进行Warm-up, 使用了$ 10^{-3} $的学习率. 仅训练Indexer 1000步, 每一步包含16个128K长度的序列, 总计使用了2.1B的tokens.
目标: 让新加入的, 未经训练的Indexer学会如何像原有的全注意力机制一样去”关注”重要的token. 具体方法如下:
- 冻结主体: 保持原模型参数不变, 确保模型的原有能力不被破坏.
- 保持密集注意力: 让模型继续在全注意力模式下运行, 这样就能拿到一个”标准答案”.
- 构建”标准答案”: 将原模型所有注意力头的注意力分数加起来, 再进行L1归一化. 这一步的
核心思想是: 一个token的重要性, 可以近似地看作它在所有注意力头中获得的总关注度. 这个聚合后的分布就成了Indexer学习的”模仿对象”.- KL散度损失 (公式3): 这个损失函数的目标是让Indexer输出的概率分布(通过Softmax得到)尽可能地接近”标准答案”. 这本质上是一种类似于知识蒸馏的做法, 将复杂的主注意力机制的”知识”蒸馏到了轻量级的Indexer中.
整个阶段只用了1000步, 2.1B tokens. 这说明给Indexer一个好的初始状态并不需要大量的计算.
Sparse Training Stage 在Indexer Warm-up之后, 引入了细粒度的token选择机制, 并优化所有模型参数以使模型适应DSA的稀疏模式. 在此阶段, 仍然保持将Indexer输出与主注意力分布对齐, 但只考虑被选中的token集合
$ \begin{aligned}
& S_t=\left{s \mid I_{t, s} \in \operatorname{Top}-\mathrm{k}\left(I_{t,:}\right)\right}: \
& \quad \mathcal{L}^I=\sum_t \operatorname{DKL}\left(p_{t, S_t} | \operatorname{Softmax}\left(I_{t, S_t}\right)\right)
\end{aligned} $(4)
值得注意的是, 作者将Indexer的输入从计算图中分离(detach)出来, 以进行独立优化. Indexer的训练信号仅来自$ \mathcal{L}^{I} $, 而主模型的优化则仅依据语言建模损失. 在这个稀疏训练阶段, 使用了$ 7.3×10^{-6} $的学习率, 并为每个Query token选择2048个KV token. 同时训练主模型和Indexer 15000步, 每一步包含480个128K长度的序列, 总计使用了943.7B的tokens.
目标: 激活稀疏模式, 并让整个模型适应这种新的, 信息输入受限的工作方式.方法如下:
- 引入Top-k: 正式启用稀疏注意力, 每个token只关注得分最高的2048个历史token.
- 解冻所有参数: 主模型和Indexer一起参与训练.
- 分离优化 (Detach): 这是一个非常关键的设计.
Indexer: 继续通过KL散度损失(公式4)进行”模仿学习”, 但此时的模仿对象和模仿行为都只发生在被选中的top-k子集上. 这种持续对齐保证了Indexer不会在后续训练中”跑偏”.主模型: 只根据标准的语言建模损失(即预测下一个词的损失)进行优化.
- k=2048: 这个选择是在效率和性能之间的一个权衡. 2048个token对于128K的上下文来说只占了1.6%, 极大地减少了计算量, 但又保留了足够的信息以维持性能.
关于分离: 如果不分离, 语言建模损失的梯度会通过主注意力模块一直反向传播到Indexer. 这会使得Indexer的训练目标变得非常复杂和不稳定: 它既要模仿主注意力的分布, 又要帮助模型更好地预测下一个词. 这种双重目标可能会导致优化困难. 分离优化使得两个模块各司其职, 训练过程更加稳定可控.
后训练 (Post-Training)
DeepSeek-V3.2-Exp的后训练也采用了与稀疏持续预训练阶段相同的稀疏注意力方式. 为了严格评估引入DSA的影响, 对于DeepSeek-V3.2-Exp, 保持了与DeepSeek-V3.1-Terminus相同的后训练流程, 算法和数据, 具体细节如下.专家蒸馏 (Specialist Distillation). 对于每个任务, 最初都开发一个专用于该特定领域的专家模型, 所有专家模型都从同一个预训练的DeepSeek-V3.2基础检查点进行微调. 除了写作任务和通用问答, 框架还包含了五个专业领域: 数学, 竞赛编程, 通用逻辑推理, Agent式编程和Agent式搜索. 每个专家模型都通过大规模强化学习(RL)进行训练. 此外, 使用不同的模型来为长思维链推理(思考模式)和直接响应生成(非思考模式)生成训练数据. 一旦专家模型准备就绪, 它们就被用来为最终的检查点生产领域特定的数据. 实验结果表明, 在蒸馏数据上训练的模型所达到的性能水平仅略低于领域专家模型, 并且通过后续的RL训练可以有效消除这一性能差距.
混合RL训练 (Mixed RL Training). 对于DeepSeek-V3.2-Exp, 仍然采用GRPO作为RL训练算法. 与之前DeepSeek模型采用多阶段强化学习不同, 将推理, Agent和人类对齐训练合并到了一个RL阶段. 这种方法有效地平衡了不同领域间的性能, 同时规避了多阶段训练范式中常见的灾难性遗忘问题. 对于推理和Agent任务, 采用了基于规则的结果奖励, 长度惩罚和语言一致性奖励. 对于通用任务, 采用了一个生成式奖励模型, 其中每个提示都有其自己的评估标准. 奖励设计精心平衡了两个关键的权衡: (1) 长度与准确性, (2) 语言一致性与准确性.
这一段信息量很大, 也算是披露了V3.1的后训练过程.
首先完全沿用V3.1的后训练流程, 包括专家蒸馏和混合RL训练. 这排除了后训练方法不同可能带来的性能差异, 使得最终的性能对比能够更纯粹地反映DSA架构本身的影响. 其次对于专家蒸馏: “先分后合”的策略. 先为各个专业领域训练专家模型, 再用这些专家模型生成高质量数据来”教”最终的通用模型. 这是一种高效扩展模型能力的方法. 然后混合RL训练: 将多个RL目标(推理, Agent, 对齐)合并在一个阶段, 解决了多阶段训练中常见的”灾难性遗忘”问题(即模型在学习新能力时忘记了旧能力). 这表明模型架构的健壮性, 能够同时优化多个复杂目标.
最后精心设计的奖励: 作者提到了在奖励设计中平衡”长度 vs 准确性”和”语言一致性 vs 准确性”, 同时特别是对于通用任务是不是已经用上了GRM? , 针对通用的Reward Model设计上采用了模型自己生成Principal的多维度打分评价体系,并根据这些生成的原则来产生评论, 并基于评论给出最终的Point-Wise打分. 通过这样的Reward Model设计非常巧妙的提高了模型本身的泛化能力.
评估
**模型能力 (Model Capabilities).** 在一系列专注于不同能力的基准测试上评估了DeepSeek-V3.2-Exp, 并将其与DeepSeek-V3.1-Terminus在表1中进行了比较.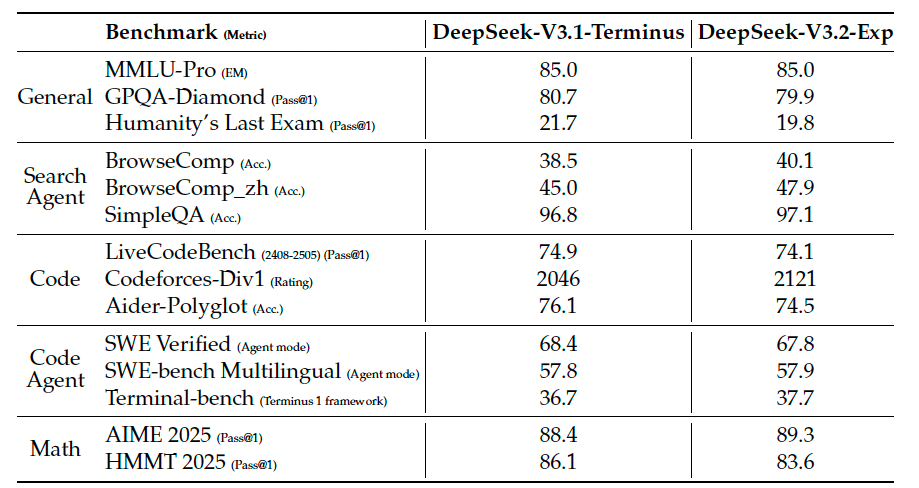
尽管DeepSeek-V3.2-Exp在长序列上的计算效率显著提升, 但并未观察到与DeepSeek-V3.1-Terminus的差距.
表格中的数据显示, DeepSeek-V3.2-Exp(稀疏)和DeepSeek-V3.1-Terminus(密集)在各大基准测试上的表现基本持平. 在MMLU-Pro, SWE-bench等测试上分数几乎完全相同, 在BrowseComp, Codeforces, AIME等测试上甚至略有提升.
另外还有一份在Model Card上的数据
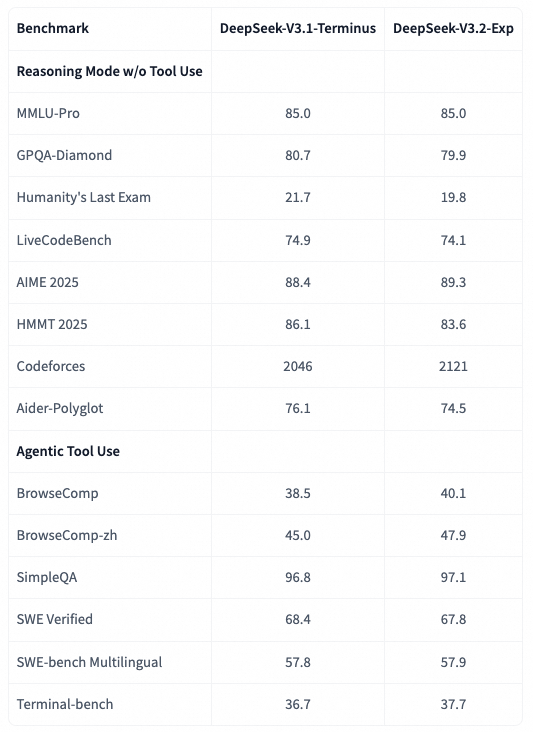
此外, 还比较了DeepSeek-V3.2-Exp和DeepSeek-V3.1-Terminus的强化学习训练曲线, 如图所示. 两模型在BrowseComp和SWE Verified上的性能在整个训练过程中都稳步提升, 且曲线非常贴近, 这反映了DSA的训练稳定性.
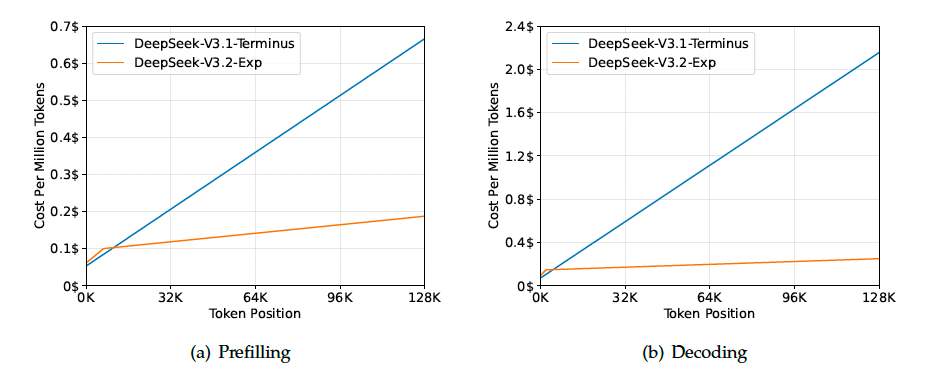
推理成本 (Inference Costs). DSA将主模型的核心注意力复杂度从$ O\left(L^2\right) $降低到了$ O\left(Lk\right) $, 其中$ k(\ll L) $是被选中的token数量. 尽管Indexer仍然具有$ O\left(L^2\right) $的复杂度, 但与DeepSeek-V3.1-Terminus中的MLA相比, 它需要的计算量要少得多. 结合优化的实现, DSA在长上下文场景下实现了显著的端到端加速. 图3展示了DeepSeek-V3.1-Terminus和DeepSeek-V3.2-Exp的token成本如何随着token在序列中的位置变化而变化. 这些成本是根据部署在H800 GPU上的实际服务的基准测试估算得出的, GPU租用价格为每小时2美元. 需要注意的是, 对于短序列的预填充(prefilling), 专门实现了一种Mask MHA模式来模拟DSA, 这在短上下文条件下可以实现更高的效率.
这消除了一个潜在的担忧: 稀疏机制是否会使RL这样本就不稳定的训练过程更加困难? 答案是否定的. 这表明DSA架构与复杂的RL算法能够很好地兼容, 训练过程是稳定且可预测的.
未来在真实世界中的验证 (Future Validation in Real World). 尽管内部评估显示了DeepSeek-V3.2-Exp的喜人结果, 但仍在积极寻求在真实世界场景中进行更大规模的测试, 以发现稀疏注意力架构潜在的局限性.
或许这个也是开源V3.2-EXP的原因吧, 在真正完成NSA或者其它Sparse Attention训练之前, 接受一些真实的信息反馈. 当然我猜测了几个可能的问题
- “大海捞针”失败: 真实世界中可能存在一些极端”大海捞针”任务, 关键信息恰好没有被Indexer评为高分, 导致模型失败.
- 对抗性攻击: 是否可以构造特定的输入, 故意”欺骗”Indexer, 让其关注无关紧要的信息, 从而使模型失效?
- **性能 vs **
k值的关系: 论文只给出了的结果. 如果能展示一幅图, 横轴是值, 纵轴是性能和成本, 将会更有说服力, 能够清晰地揭示性能与效率之间的权衡曲线, 当然这个代价是巨大的.另外, 从个人来看, 更期待的是NSA这样的block based sparse attention的机制. 因为最近一段时间在开发Agent相关代码的时候, 经常自己根据任务来拼凑一些block在一起, 特别是对一些复杂的agent任务, block之间的相关性是明确的.
参考资料
[1] **Mixture-of-Depths: Dynamically allocating compute in transformer-based language models: **https://arxiv.org/pdf/2404.02258











