
Cursor编程实践经验分享

Cursor编程实践经验分享
lycheeKingCursor的使用效果取决于有效的Rules、正确的开发流程和标准的Prompt。通过合理设置提示词,明确目标、上下文和任务要求,结合项目规范的Rules,能显著提升编程效率。MCP工具可进一步增强Cursor的功能,如直接搜索钉钉文档、任务分解等。但Cursor在大型需求和技术方案深度研究方面仍存在不足,需借助专业工具如DeepResearch或Claude 4.0完成复杂分析任务。未来方向是探索AI在更多研发流程中的提效可能 。
01 写在前面
本文是近两个月的实践总结,结合在实际工作中的实践聊一聊Cursor的表现。记录在该过程中遇到的问题以及一些解法。问题概览(for 服务端):
- 不如我写的快?写的不符合预期?
- Cursor能完成哪些需求?这个需求可以用Cursor,那个需求不能用Cursor?
- 历史代码分析浅显,不够深入理解?
- 技术方案设计做的不够好,细节缺失,生成代码的可用性不够满意?
02 Cursor项目开发流程

通过近两个月的实践,在编程中,cursor的表现取决与有效的Rules+正确的开发流程+标准的Prompt。在日常需求中按照该流程开发,目前对于编程的提效是接近预期的。在日常使用中主要以提效为主,不纠结一定要cursor写。下一步我们的方向是基于研发的流程分析,我们还有哪些流程可以使用 AI帮助我们提效?本篇文章主要是介绍我们实践的一些心得体会,以及对未来的一些展望。
03 Cursor如何用好
1.标准的Prompt
2.好用的Rules
3.合理的开发流程
4.有帮助的mcp
标准的PE如何写
其实在聊这个问题,大家可能会说有时候好用有时候不好用。大家对好用的第一感知就是一句话沟通后Cursor能完成至少 40-60% ,不好用则是超过三次后完成的不如预期。
Cursor用好的第一步是首先学会和cursor对话,是否真的会聊?我们工程研发是否会写PE( Prompt Engineering ),对于研发工程同学,其实Prompt对于我们是有些门槛,但是在端到端的过程中,Prompt是我们的入门的必备技能。准确有效的提示词能能让Cursor效率事半功倍。
接下来按照每个步骤分析应该给到Cursor的信息,可以不严格按照此格式,精髓是把我们的目标+上下文+要求给到Cursor。
分享一套我们团队同学总结的Prompt经验:
目标:明确Cursor到底是写技术方案、生成代码还是理解项目;
上下文信息:必要的背景信息。
要求:
Cursor要做的事:拆解任务,让Cursor执行的步骤;
Cursor的限制;
项目理解
1 | # 目标请你深入分析当前代码库,生成项目梳理文档。 |
1 | # 目标请你根据需求文档,生成技术方案。注意你只需要输出详细的技术方案文档,现阶段不需改动代码。(此时需求文档已经以文档的形式放到了我们的项目中) |
1 | # 目标请你按照设计好的方案,生成代码。 |
1 | # 任务请你为《xx.go》文件生成单测。 |
04 好用的CursorRules
经过两个月的实践, 目前Rules趋于稳定 ,从需求到自测基本可以满足我们的日常开发。
自己生成Rules
在v0.49版本支持自动生成rules,直接输入/,即可看到生成规则模式;自动生成规则可以有效的把自己的习惯或者项目的开发规范通过Rules的形式落地而不是每次反复在Prompt中提醒约束;
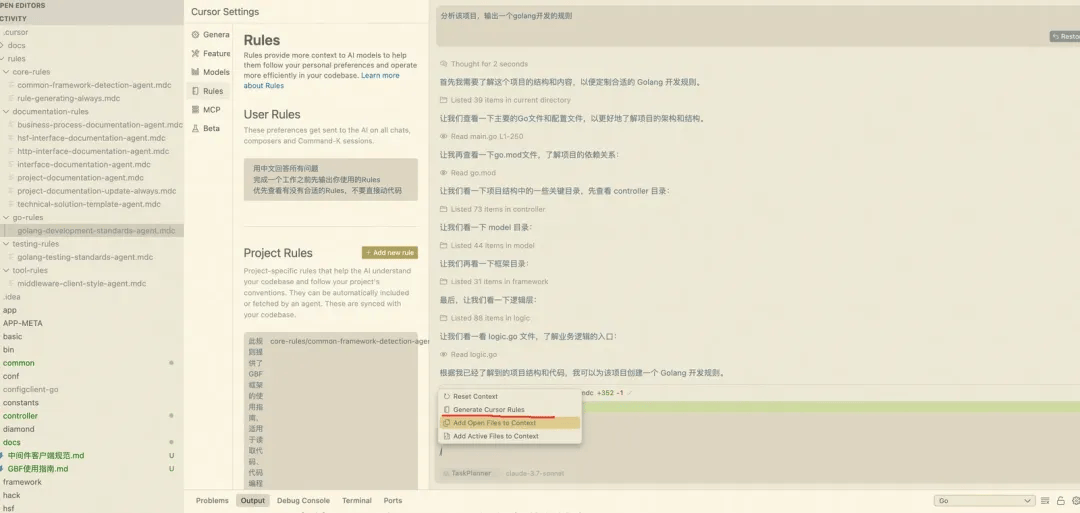
比如:生成golang项目开发规范
golang开发规范,仅适用于当前项目
1 | --- |
结合当前项目总结出golang开发规范,可以免去我们花大量时间补充。最近新发布的版本, 不建议大家马上更新,涉及到隐私模式权限问题,会有代码泄漏的风险,可以先等等。
新增自动记忆模块:简单来说,这个功能会根据我们和Cursor的历史对话,来自动创建User Rules。只要你的项目持续迭代,那么这个User Rules就会自动更新。之前我们使用每次chat新开就是 它的记忆在每次会话(session)之间会完全重置 ,目前新增了该模块,通过自动创建user rules变得更懂你。
一些有帮助的rules
1.项目梳理文档Rule:通过已有的代码进行codebase整理输出项目架构、技术实现细节等
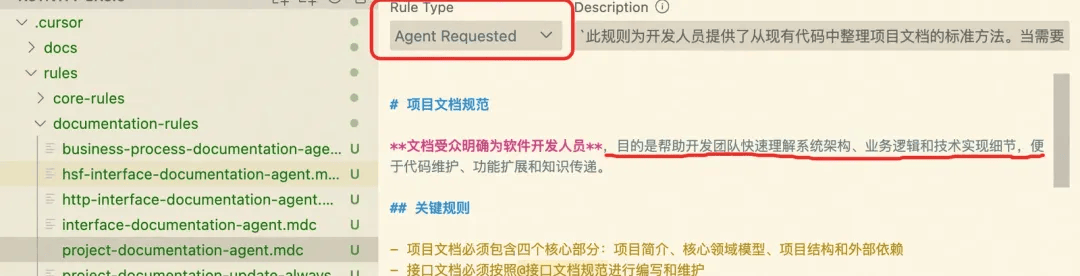
具体的Rule给到大家一个参考:
项目梳理文档Rule
1 | # 项目文档规范 |
两个rule可以亲自试试效果,第二个描述规范了Cursor要深入检索,但是目前免费能用的模型很难做到,新出来的Claude4.0可以完成复杂任务的分析研究。
梳理项目Rule
1 | # 代码分析规则 |
2.技术方案详细设计Rule:在Cursor输出具体的方案,按照此Rule的结构生成,包含了核心实体、具体的时序交互、核心api的修改等等
技术方案详细设计Rule
1 |
|
3.中间件Rule:项目开发用到的一些比较常见的中间件的调用规范。
中间件使用规范
1 | --- |
05 MCP
MCP作为cursor的加强工具,可以让工作中更加流畅。分享几个常用的MCP平台,大家有需求的可以尝试使用,比自己开发mcp省时方便。
Smithery - Model Context Protocol Registry
▐ 简单介绍我日常会用到的MCP
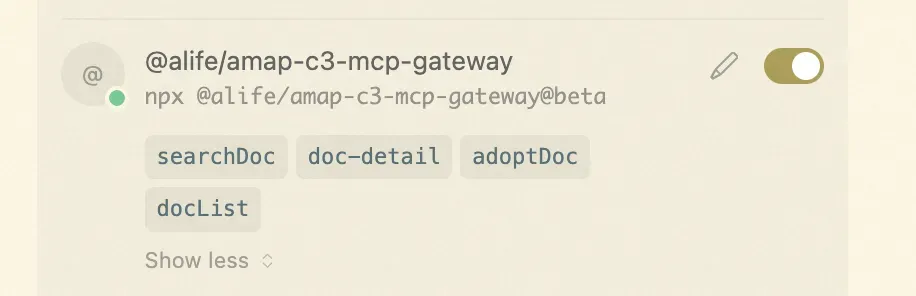
- 钉钉文档搜索
在我们日常引用到内部的文档比较麻烦,可能需要把文章下载为md文档,在加载到cursor中,使用该MCP可以直接使用,不需要来回转换,比较便利,这个是我们前端的团队同学开发的mcp
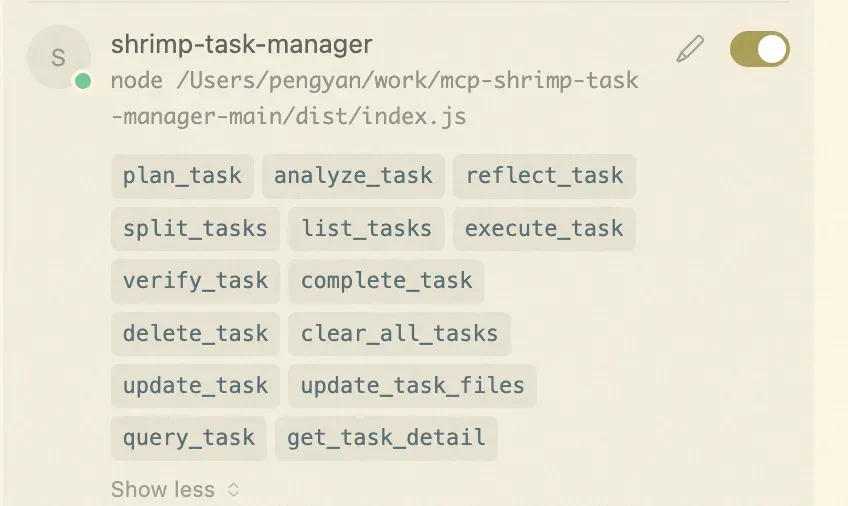
- 任务分解大师
对于cursor的实践,需求拆分到合理的粒度cursor的效果更好些,对于一些复杂的需求可以尝试使用任务分解的工具,能帮助cursor更加专注
05 Cursor现阶段做得不好的点
经过这段时间的实践,在编程领域Cursor做的很不错,在一些比较大的需求上,表现的效果不稳定,比如技术方案需要参考业界已有的优秀案例为参考,能设计出有水平的技术方案,业界对这部分的定义称为-深度研究。说到深度研究,鼎鼎有名的就是今年发布的DeepResearch,简单介绍一下:
DeepResearch深度研究
先说一下背景,为什么会讨论到深度研究:
- 目前Cursor在根据已有的代码做codebase,梳理项目,发现他很偷懒,梳理的浅显;
- 对于服务开发来说,一个大型项目是需要充分的调研&技术选型,目前cursor能做到的是给出一个方案,但是大多数是不可用的而且也没有依据不可追溯;
对于目前Cursor是无法按照预期完成以上两个任务,经过调研,发现了DeepResearch深度研究。
深度研究通常包括以下几个步骤:
1.规划:AI处理研究任务并独立规划搜索过程和搜索查询;
2.信息搜索:AI搜索多种来源的信息并过滤不重要的内容;
3.分析:AI”阅读”所有收集的文本,提取重要事实,比较来源并识别矛盾;
4.结构化和整理:AI以清晰结构化的报告形式呈现结果;
目前主要提供深度研究功能的平台有:
- Perplexity Pro
- ChatGPT Pro
- Gemini Advanced
ata有分析对比多这几个平台的差异性,大家可以自行前往查看。
Deep Research 和Cursor的区别,以下是Cursor给出的答案:

以上能回答能解释我们一部分的疑惑,为什么codebase回答的浅显,目前看深入研究并不是他擅长的,研究的活要交给专业的DeepResearch来做。相应的阿里千问也支持深度思考,官网地址: https://chat.qwen.ai/c/2e6f01d2-81ba-45ba-b943-9997970f07b8
由于是商业化的模型闭源,其实内部真实的原理如何做到如此强大是无法清晰了解,借此机会了解了一下AutoGPT。
06 AutoGPT
Auto-GPT是什么?
Auto-GPT是一种基于OpenAI的GPT(Generative Pre-trained Transformer)大语言模型的自动化智能体(Agent)框架。它的核心思想是让AI能够自主地分解目标、规划任务、执行操作,并根据反馈不断调整自己的行为,最终实现用户设定的复杂目标。
其中AutoGPT算是其中一个比较具有代表性的Agent
主要特点:
1. 自主性 : Auto-GPT可以根据用户给定的高层目标,自动生成子任务并逐步完成,无需人工干预每一步。
2. 任务分解与执行 : 它会将复杂目标拆解为多个可执行的小任务,并自动调用各种工具(如搜索、代码生成、文件操作等)来完成这些任务。
3. 循环反馈 : Auto-GPT会根据每一步的结果自动调整后续计划,直到目标达成或遇到无法解决的问题。
4. 插件与扩展性 : 支持集成第三方API、数据库、网络爬虫等多种能力,适合自动化办公、数据分析、内容生成等场景。
典型应用场景:
- 自动化写作、报告生成
- 自动化代码编写与调试
- 自动化数据收集与分析
- 智能助手、RPA(机器人流程自动化)
与普通GPT的区别:
- 普通GPT模型通常是“问答式”或“单轮对话”,需要用户逐步引导。
- Auto-GPT则具备“自主规划与执行”能力,可以像一个智能体一样,自动完成一系列复杂任务。
举例说明:
假如你让Auto-GPT“帮我调研2024年AI领域的最新趋势并写一份报告”,它会自动:
1. 拆解任务(如:查找资料、整理要点、撰写报告)
2. 自动上网搜索、收集信息
3. 归纳整理内容
4. 生成结构化报告
5. 甚至可以自动保存为文件或发送邮件
AutoGPT的原理
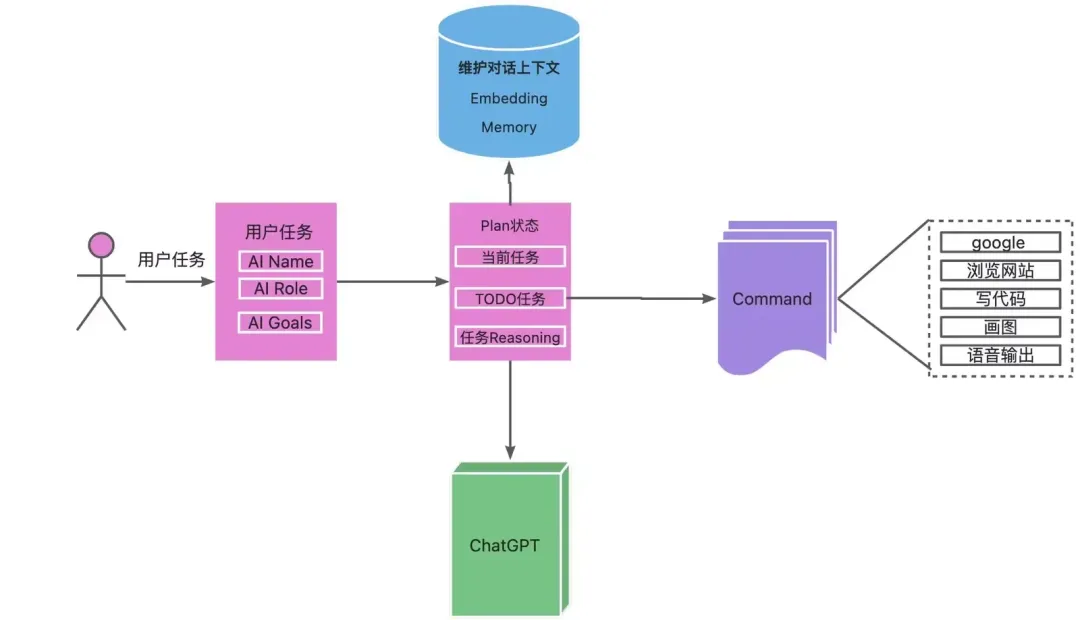
AutoGPT组成
1.用户交互界面CLI:用户可以在这里输入任务和目标,查看AutoGPT的执行过程和结果。
2.PromptManager:这是AutoGPT的核心模块,负责根据任务和目标生成适当的提示,并调用GPT-4或GPT-3.5来获取回答。
3.LLM能力:这是AutoGPT利用的语言模型,主要是GPT-4,用于生成文本、代码、方案等内容;也可以使用GPT-3.5,用于总结信息、解决问题等功能。
4.Memory管理:这是AutoGPT的存储模块,负责将交互的结果保存到文件中,以便日后参考或复用。
5.任务管理:这是AutoGPT的控制模块,负责记录用户的目标,并根据执行情况生成新的子任务或结束任务。
AutoGPT处理流程
AutoGPT的原理是利用GPT-4和其他服务来自主执行任务,其核心是一个无限循环的程序,它可以根据用户的任务指令,自动提出问题并进行回答,从而完成任务。AutoGPT的原理可以分为以下几个步骤:
获取用户的任务指令。用户可以通过命令行或者网页界面,输入一个简单的任务指令,例如“increase net worth”。AutoGPT会接收到用户的任务指令,并将其保存在内存中。
分析用户的任务指令。AutoGPT会调用GPT-4来分析用户的任务指令,提取出其中的关键词和目标。生成Plan:
a.Use the ‘google’ command to search for articles on personal finance and investment strategies
b.Read and analyze the information gathered to determine the best course of action
执行2步生成需要执行command(包括通过google查询数据,访问网站,写代码、生成图片、调用API等),并保存结果到内存。
检查回答是否满足目标。AutoGPT会检查每个回答是否满足用户的任务指令中的目标,如果满足,则将回答保存在文件中,并继续回答下一个问题;如果不满足,则将回答丢弃,并重新生成一个新的任务列表。
重复第2~4步,直到完成所有目标或者找不到解决方法。AutoGPT会不断地重复第三步和第四步,直到回答完所有问题列表中的问题,并且所有回答都满足用户的任务指令中的目标;或者无法生成更多有效的问题列表,并且无法找到更多有效的信息来源或者服务。此时,AutoGPT会结束任务,并将保存在文件中的所有回答输出给用户。
以上就是AutoGPT的原理,它利用了GPT-4强大的语言生成能力和其他服务丰富的信息资源,实现了一种自 主执行任务的人工智能应用程序。AutoGPT不需要用户提供详细的指令和提示,只需要设定总体目标,就可以让AI自己去思考和行动,完成各种复杂和有价值的任务。
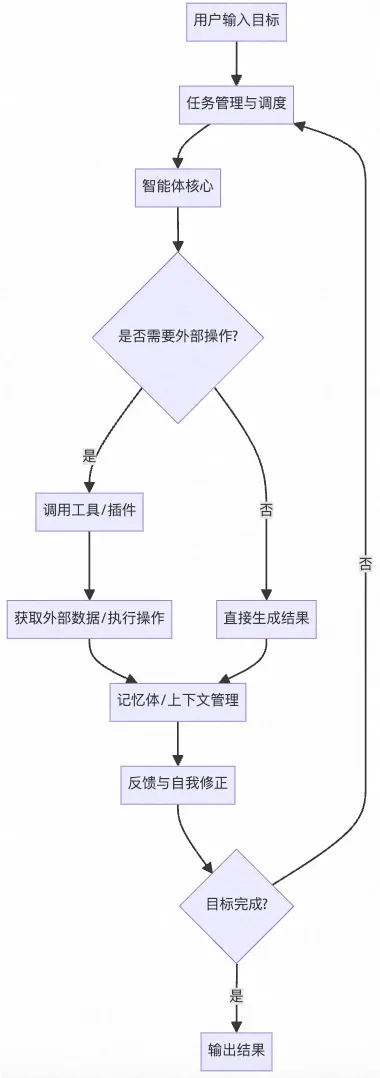
AutoGPT无限循环的终止机制
AutoGPT通过以下几种机制来防止和终止无限循环:
1. 执行步数限制 (Step Limit)
- AutoGPT设置了最大执行步数限制,通常默认为50-100步
- 当达到预设的步数上限时,系统会自动停止执行
- 用户可以根据任务复杂度调整这个限制
2. 令牌使用限制 (Token Budget)
- 设置API调用的令牌预算上限
- 当消耗的令牌数量接近或达到预算时,系统停止执行
- 防止因循环导致的过度API调用成本
3. 时间超时机制 (Timeout)
- 设置任务执行的最大时间限制
- 超过时间阈值后自动终止执行
- 防止任务无限期运行
4. 循环检测算法
- 状态重复检测: 监控系统状态,如果连续几次执行相同或相似的操作,会触发循环警告
- 行为模式识别: 分析执行序列,识别重复的行为模式
- 目标完成检查: 定期评估是否朝着目标前进
5. 人工干预机制
- 手动停止: 用户可以随时手动终止执行
- 确认模式: 在关键步骤需要人工确认才能继续
- 监控仪表板: 实时显示执行状态,便于监控
- 智能终止条件
- 目标达成检测: 当系统判断目标已完成时自动停止
- 无进展检测: 如果连续几步没有实质性进展,触发停止机制
- 错误累积: 当错误次数超过阈值时停止执行
7. 资源消耗监控
内存使用监控: 防止内存溢出
CPU使用率检查: 避免系统资源耗尽
磁盘空间检查: 防止存储空间不足
AutoGPT内置的Prompt系统
1.系统级内置Prompt
AutoGPT内置了多个核心prompt模板,用于指导AI的行为:
主系统Prompt
1 |
|
思考过程Prompt
1 | THINKING_PROMPT = """ |
2.任务特定Prompt模板
研究分析Prompt
1 |
|
3.命令执行Prompt
网络搜索的prompt
1 | WEB_SEARCH_PROMPT = """ |
4.自我反思Prompt
1 | REFLECTION_PROMPT = """ |
5.错误处理Prompt
1 | ERROR_HANDLING_PROMPT = """ |
6.Prompt优化特性
1 | CONTEXT_MANAGEMENT = """ |
▐ Claude4.0
好吧,说到这里如果现在Claude模型赋能该能力,可以进行深度研究模式,能直接解决我们现在的诉求,切换不同的模式满足不同的需求,未来是必达的!
Claude4.0模型的发布还是很鼓舞人心的!

新功能:
- 扩展推理与工具调用功能(Extended thinking with tool use):两款新模型均可在进行深入思考时调用工具(如 网页搜索 ),可在推理与工具使用之间切换,以提升回答质量
- 新增模型能力:支持并行调用多个工具、更精准执行指令;若开发者开放本地文件访问权限,Claude还能大幅提升记忆能力,提取并保存关键事实,帮助模型保持上下文一致性并逐步构建隐性知识
- Claude Code 正式发布:在预览阶段获得大量积极反馈后,扩展了开发者与Claude协作方式。现支持通过GitHub Actions后台运行,并与VS Code和JetBrains原生集成,可在代码文件中直接显示修改,提升协作效率。
- 新增API能力:Anthropic API推出 四项新功能 ,助开发者构建更强大AI智能体,包括代码执行工具、MCP连接器、文件API以及提示缓存功能(最长可达1h)
Claude Opus 4与Sonnet 4属混合型模型,支持两种运行模式:
- 即时响应
- 深度推理
关于这两种模式的解释:Anthropic通过综合方法解决了AI用户体验中的长期问题。Claude 4系列模型在处理简单查询时能够提供接近即时的响应,对于 复杂问题则启动深度思考模式 ,有效消除了早期推理模型在处理基础问题时的延迟和卡顿。这种双模式功能既保留了用户所期待的即时交互体验, 又能在必要时释放深度分析能力 。系统根据任务的复杂性动态分配计算资源,实现了早期推理模型难以达到的平衡。记忆的持久性是Claude 4系列的另一项重大突破。这两款模型具备从文档中提取关键信息、创建摘要文档的能力,并在获得授权后实现跨会话的知识延续。这一能力攻克了长期制约AI应用的[记忆缺失]难题, 使AI在需要持续数日或数周上下文关联的长期项目中真正发挥其作用 。 这种技术实现方式与人类专家开发知识管理系统的方式相似,AI会自动将信息整理成适合未来检索的结构化格式。
通过这种方式,Claude 4系列模型能够在长时间的互动过程中不断深化对复杂领域的理解。












